Prune your AI budget.
Most enterprises let their AI spend grow wild — every trivial prompt routed to the most expensive frontier model. Podar trims it back: the right model for each task, billed only on the waste we cut away.

AI wastage, and overspend for nothing.
Enterprises adopted AI faster than they built any discipline around how it is consumed. The result is structural, invisible waste. Three patterns drive almost all of it.

Capability overspend
Frontier-tier models invoked for tasks a small, fast model would have nailed for a fraction of a cent.
Paying twice
The same answer regenerated across teams, sessions, and applications. No shared memory of what was already produced.
No common unit
Spend is reported in tokens, dollars, and seats — never in efficiency. You cannot manage what you cannot measure.

"40–70% of a typical AI budget is recoverable without any loss of quality. That recoverable slice is Podar's entire reason to exist."
One endpoint in. The right model out.
Employees notice nothing change except that answers stay good. Finance watches AI Wastage fall and AI Yield climb week over week.

- 01ReceiveA single endpoint your apps and people prompt — drop-in compatible.
- 02ScoreEvery prompt is rated for complexity, sensitivity, and required quality.
- 03CacheSemantically similar answers are reused. You stop paying twice.
- 04RouteMulti-gateway fabric finds the cheapest supply path to a good-enough model.
- 05EscalateHard prompts climb the chain to frontier models. Easy ones never leave the basement.
- 06MeasureRealized savings recorded prompt by prompt — the meter our fee runs on.
We orchestrate across every major AI gateway so customers never depend on any one of them.
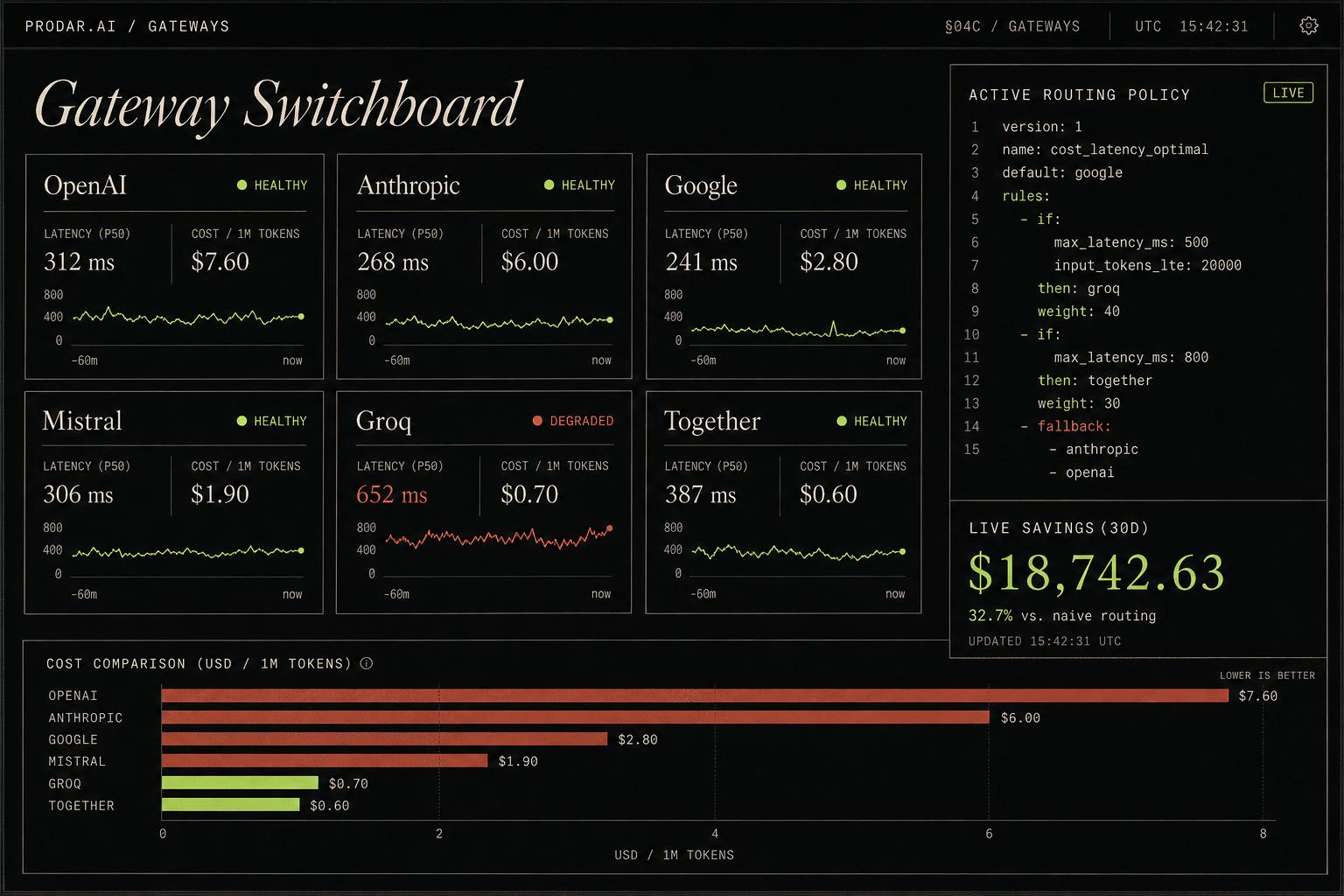
Every gateway, one switchboard.
Connect, health-check, and route across every major AI gateway from a single pane. No single-vendor lock-in.
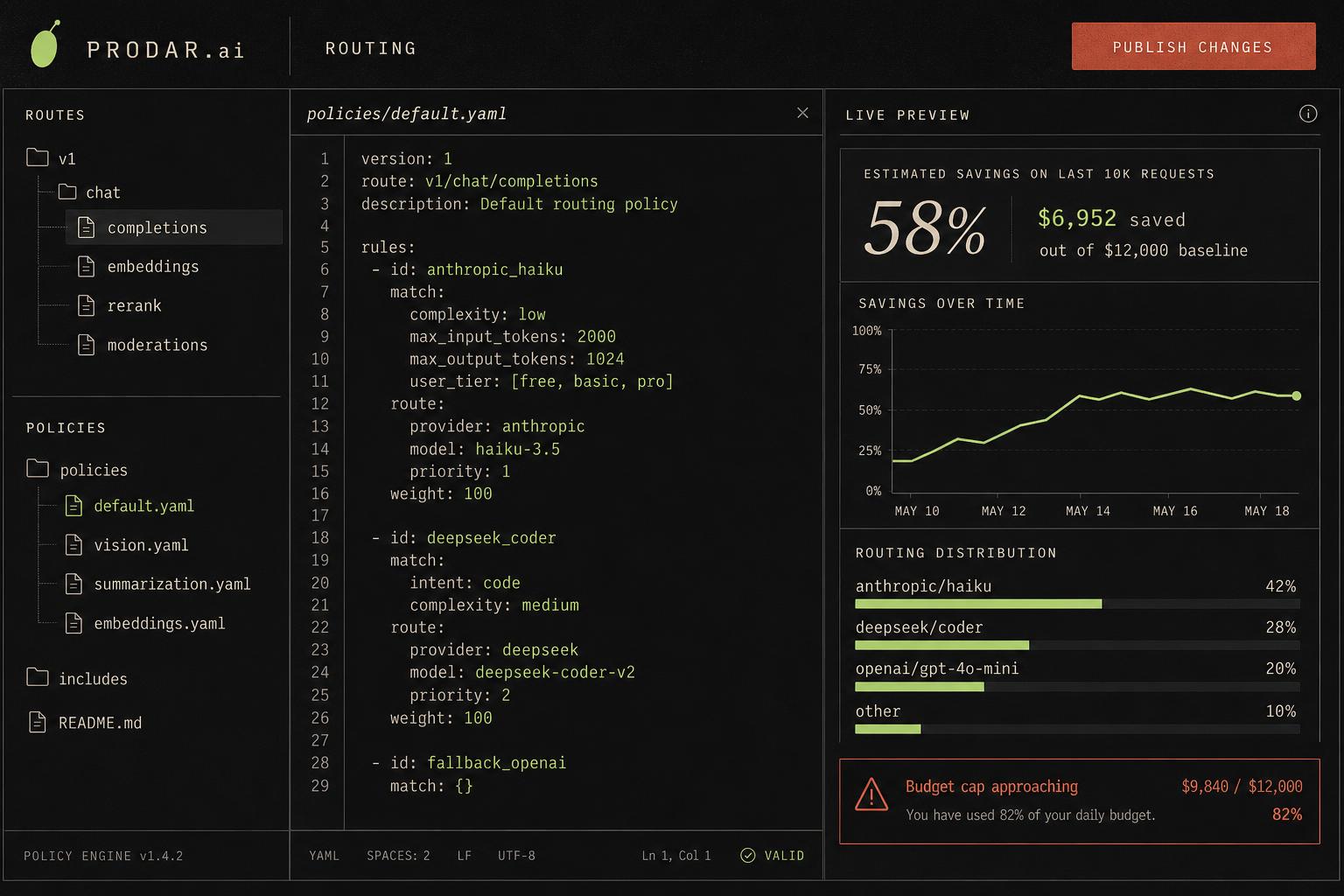
Policies as code. Savings as preview.
Engineering writes routing rules in plain YAML. Every change shows the realized savings on the last 10,000 requests before it ships.
Trim the prompt before it leaves.
Prompt optimization analyzes every AI request before execution and removes unnecessary tokens while preserving essential context, intent, and constraints.
Cut dead weight
Remove duplicated information, irrelevant conversation history, unused metadata, and overly verbose instructions that inflate token count.
Compress without loss
Redundant examples and formatting that does not affect the expected answer are stripped away. The signal stays intact.
Preserve intent
User intent, required context, and constraints are protected. Response quality holds while cost drops.
One request, many specialists.
Podar decomposes complex AI requests into specialized subtasks, routes each subtask to the most efficient model, then validates and recomposes the final output — cutting cost while raising quality.
Decompose
Complex requests are broken into discrete subtasks — extraction, classification, reasoning, writing, validation.
Route
Each subtask is dispatched to the model best suited for the job, balancing capability against cost and latency.
Validate
Outputs are checked against schemas, constraints, and quality signals before they advance downstream.
Recompose
Validated fragments are stitched back into a single, coherent response — indistinguishable from a one-model call, at a fraction of the cost.
One screen the CFO and the CTO both read.
AI Yield, spend saved, tokens routed, latency, cache hit rate, and the full routing waterfall — updated in real time, exportable to any FinOps tool.


AI Yield + AI Wastage = 100%
One identity, every customer review. The category-defining vocabulary for AI cost discipline.
The share of AI spend that bought necessary work at an appropriately sized model. The headline health metric we report to your CFO.
Money spent overpaying for capability the task never needed, or paying twice for answers we already had. Exactly what we delete.
"This month your AI Yield rose from 67% to 82%, we recovered $214K of pure overspend, and your Quality Index held flat."

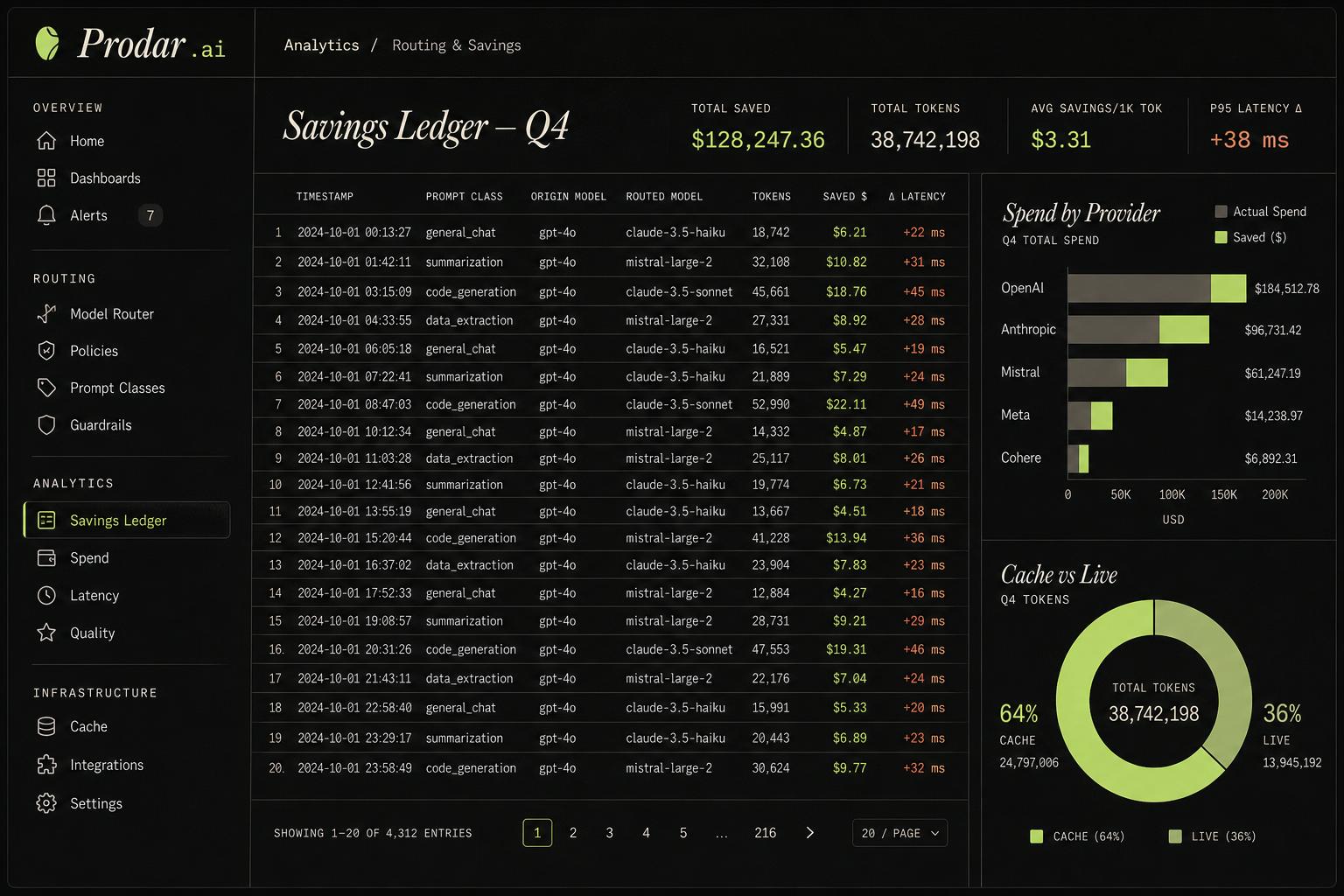
Every saved dollar, accounted for.
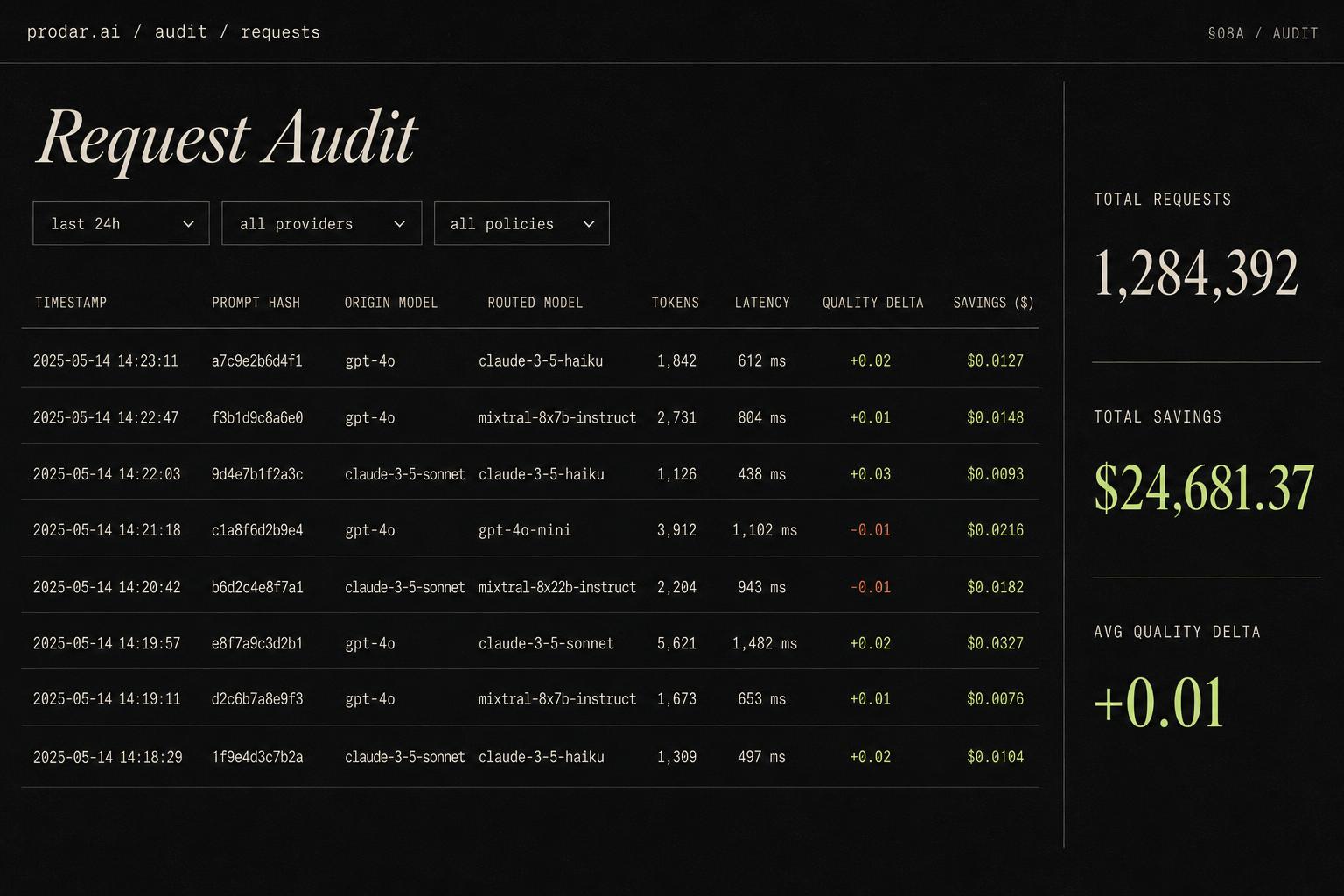
Each routed request is logged with origin model, routed model, tokens, and realized savings. The meter our fee runs on — auditable line by line.
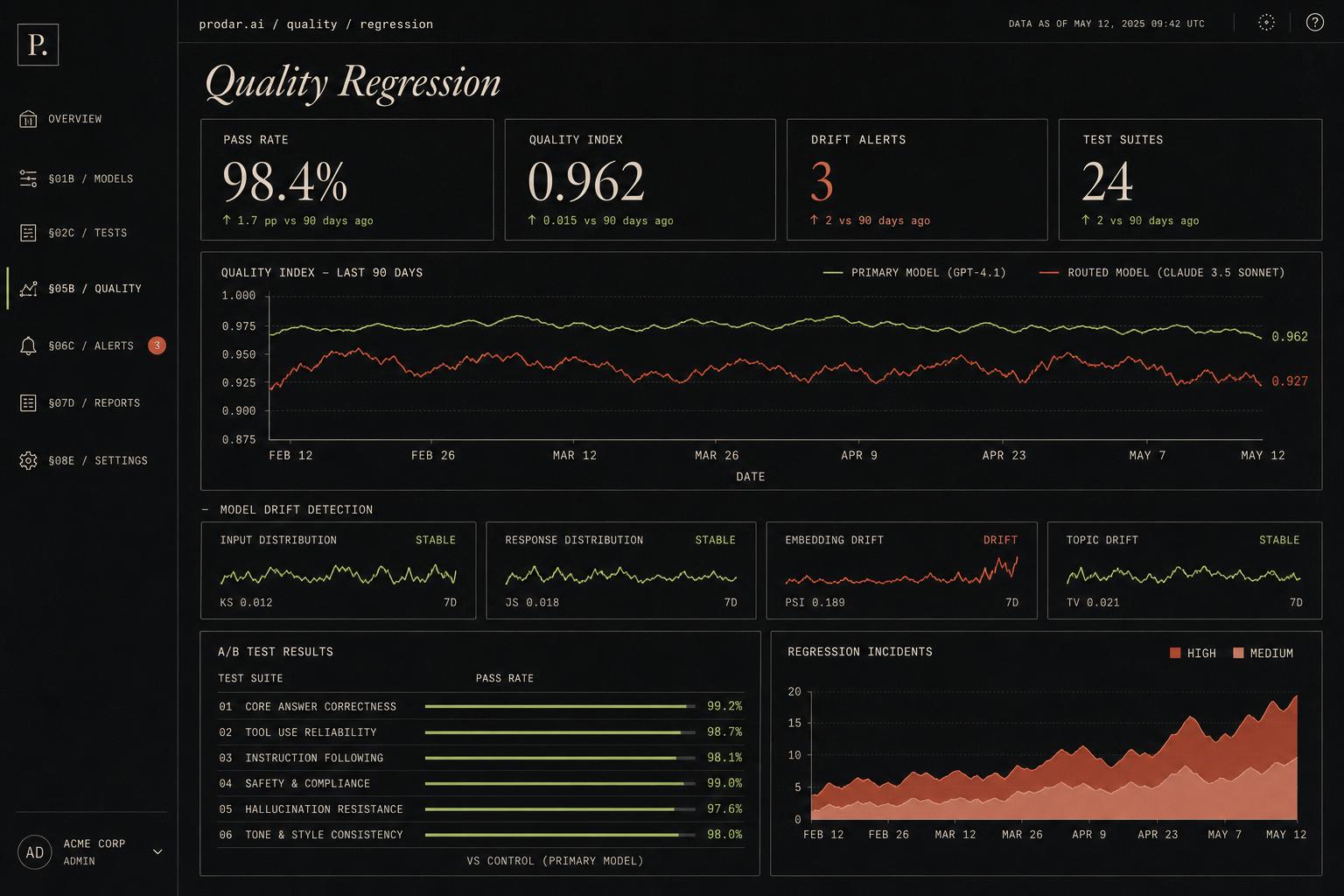
Quality that never regresses.
Automated regression suite tests every model swap before it reaches production. Quality Index stays flat while cost drops.
Fee on savings. Nothing else.
No large upfront license. No per-seat tax. We charge a percentage of the spend we verifiably remove. If we do not save you money, we do not get paid — which is exactly why customers say yes.

* Directional. Not a guarantee. Per representative account.
Every dollar saved, auditable.
The meter our fee runs on is transparent. Request-by-request savings with origin model, routed model, and quality score.
The space splits three ways. None of them deletes the bill.
Gateways
Move traffic. Don't optimize spend as an outcome.
AI-FinOps tools
Report on spend. Don't actually remove it.
Hyperscaler dashboards
Show their own consumption. Single-vendor by design.
From wedge to platform.
Routing core, semantic cache, AI Yield meter. First five paying enterprises.
Quality regression suite, multi-gateway breadth, FinOps integrations.
Autonomous optimization. Agentic-workload routing. Supply-path marketplace.
Stop paying for AI overspend that buys you nothing.
Zero-risk fee-on-savings pilot. No upfront license. No per-seat fee.